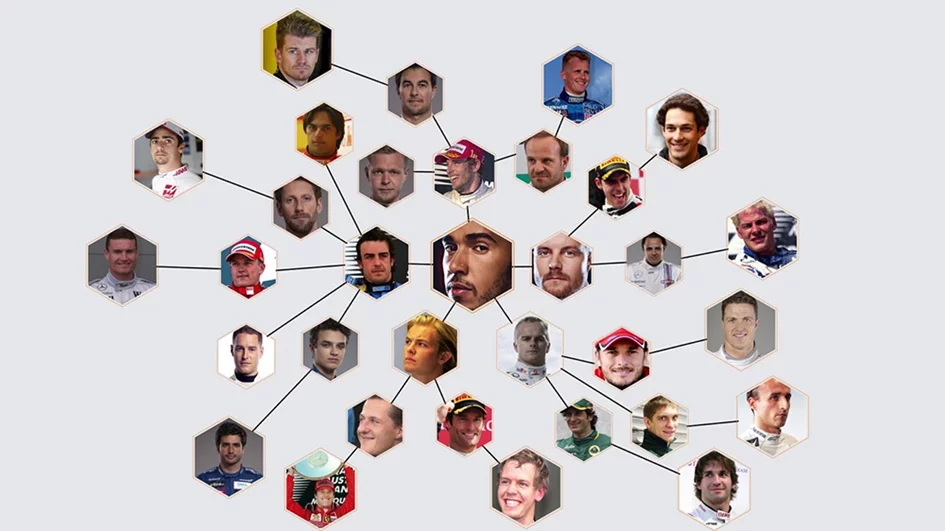
Formula 1 racing is one of the most complex sports in the world and is an amazing combination of human and machine perfection. It is this mixture that makes F1 racing, or rather the talent of the driver, difficult to interpret. However, with Amazon’s Machine Learning Solutions Lab algorithm, it is possible to measure the “speed” of the driver himself based on data.
How does AI predict the fastest Formula 1 driver of the last 40 years?
4 minutes of reading
Formula 1 racing is one of the most complex sports in the world and is an amazing combination of human and machine perfection. It is this mixture that makes F1 racing, or rather the talent of the driver, difficult to interpret. However, with Amazon’s Machine Learning Solutions Lab algorithm, it is possible to measure the “speed” of the driver himself based on data.
How many races or world championships would Michael Schumacher really have won without the technical genius of Benetton and then Ferrari? Would Lewis Hamilton really have won seven world titles if it hadn’t been for Mclaren and Mercedes? There are a lot of drivers whose talent has been hidden for a large part of their careers. But now, artificial intelligence can help pick them out of the crowd.
Formula 1 and Amazon Machine Learning Solutions Lab have been developing an algorithm over the last year, which has resulted in a tool capable of creating a ranking of the fastest drivers of the last 40 years. It uses machine learning to compare qualification scores, however, race results are not taken into account. Only pure speed on a single lap.
A team led by Formula 1 Data Systems Director Rob Smedley, Director of Broadcast and Media Dean Locke, and Chief Scientist and Senior Manager of Amazon ML Solutions Lab Dr Priya Ponnapalli contributed significantly to this. They found ways to detect outliers. These are, for example, accidents, car breakdowns or changing weather conditions. Thanks to their isolation, it was possible to create a truly fair ranking.
How does it work?
Behind the answer to the question “Who is the fastest driver?” is an absolutely enormous amount of analyzed data. AWS machine learning software combed through the results of every qualifying session since 1983, removed outliers, and normalized data to create a complex network of driver outcomes. All of which were analyzed in relation to their teammates.
The algorithm behind the solution to the problem
The algorithm uses the Massey method (a form of linear regression) to classify drivers using sets of linear equations in which each driver’s rating is calculated as the average difference in lap time relative to teammates. Additionally, when comparing the ratings of team members, the model uses the number of occurrences of the driver normalised by the number of interactions with the driver. Overall, the model gives high ratings to drivers who do exceptionally well with teammates or other strong opponents.
The goal is to assign each driver a numerical rating. This allows you to assess the advantage of the driver over others, assuming that the expected margin of difference in lap time in any race is proportional to the difference in the driver’s true internal rating.
For more mathematical readers: let xj represent each of all drivers, and rj represent the true internal evaluations of the driver. For each race, we can predict the margin of advantage or disadvantage of lap time (yi) between any pair of two drivers as:
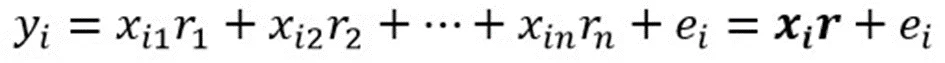
In this equation, xj is +1 for the winner and -1 for the loser, and ei is an error resulting from unexplained variations. For a given set of m observations of the game and n drivers, we can formulate a system of linear equations (m * n):
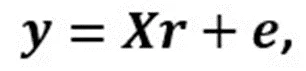
Driver ratings (r) are the solution of the equation using linear regression:
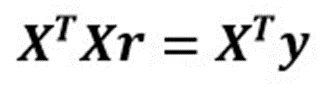
So who is the fastest?
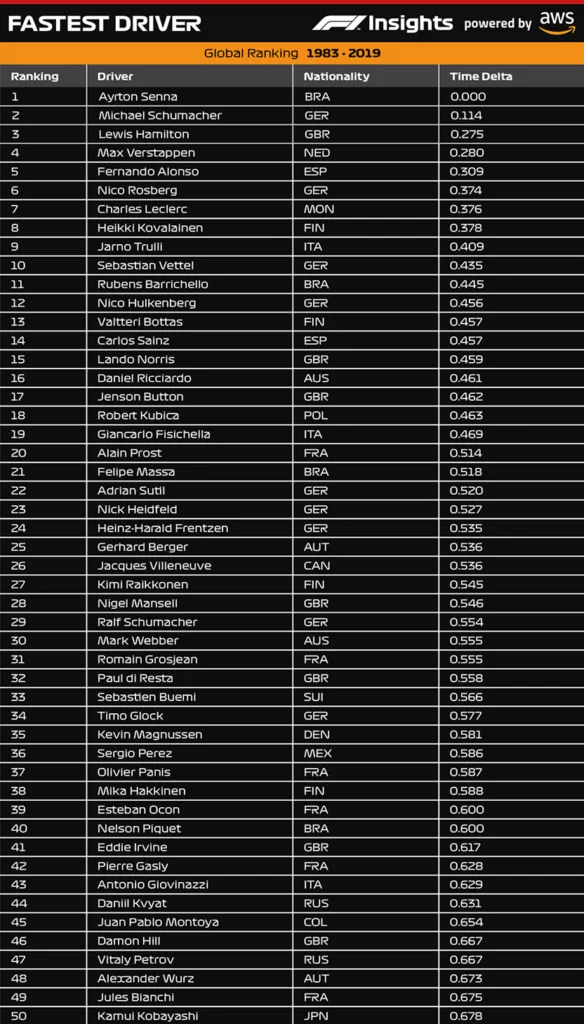
At the top of the list of the fastest drivers are:
- Ayrton Senna.
- Michael Schumacher.
- Lewis Hamilton.
- Max Verstappen
- Fernando Alonso.
The model ranks the dataset based on the speed (or qualifying times) of all drivers from today to 1983, simply ranking drivers in descending order from Driver, Rank (integer), Gap to Best (milliseconds).
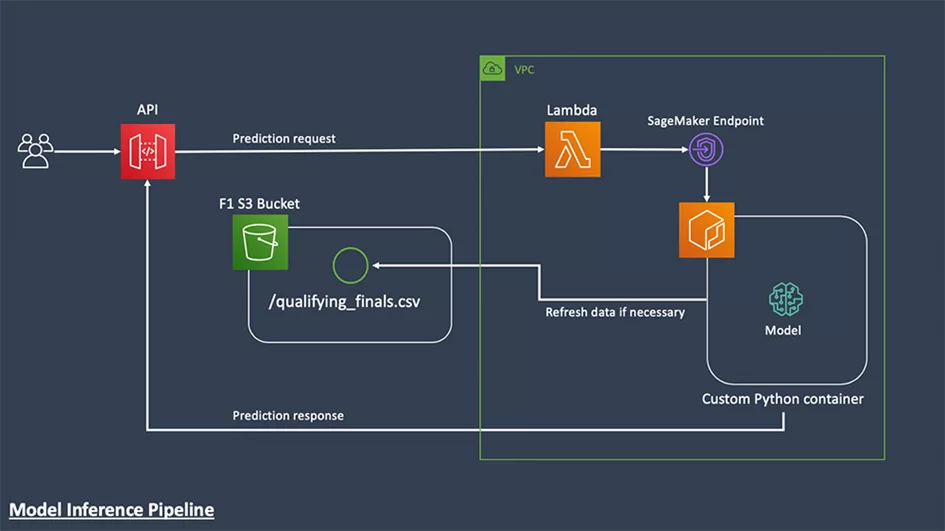
What is the role of AWS and cloud computing?
To implement the Massey method, a Python-based web server was used.
One complication was that the qualifying data used by the model is updated with new lap times after each race weekend. To remedy this, in addition to the standard request to the web server for rankings, a refresh request has also been implemented, which instructs the server to download new qualifying data from the Amazon Simple Storage Service (Amazon S3).
A model web server was implemented on the endpoint of the Amazon SageMaker model. This makes the endpoint highly accessible, as the multi-instance endpoints of the Amazon SageMaker model are distributed across multiple AZ’s by default and have built-in auto-scaling capabilities.
An added benefit is the integration of endpoints with other Amazon SageMaker features, such as the Amazon SageMaker Model Monitor, which automatically monitors model drift on the endpoint. Using a fully managed service like Amazon SageMaker means that the final architecture is very efficient. To complete the deployment, an API layer has been added around our endpoint using Amazon API Gateway and AWS Lambda. The diagram below shows this architecture in action.
Summary
There’s an old saying in the academic world that data can be used to confirm anything you want.
And while the ranking of “The Fastest Driver” may seem a little funny, the advanced data modelling used in this case is similar to those used by F1 teams to select new drivers.